How we built Townie – an app that generates fullstack apps
Townie has been completely redesigned in the past couple weeks. It’s seriously good at writing fullstack apps. This is the post about how I prototyped this new version of Townie a couple weeks ago.
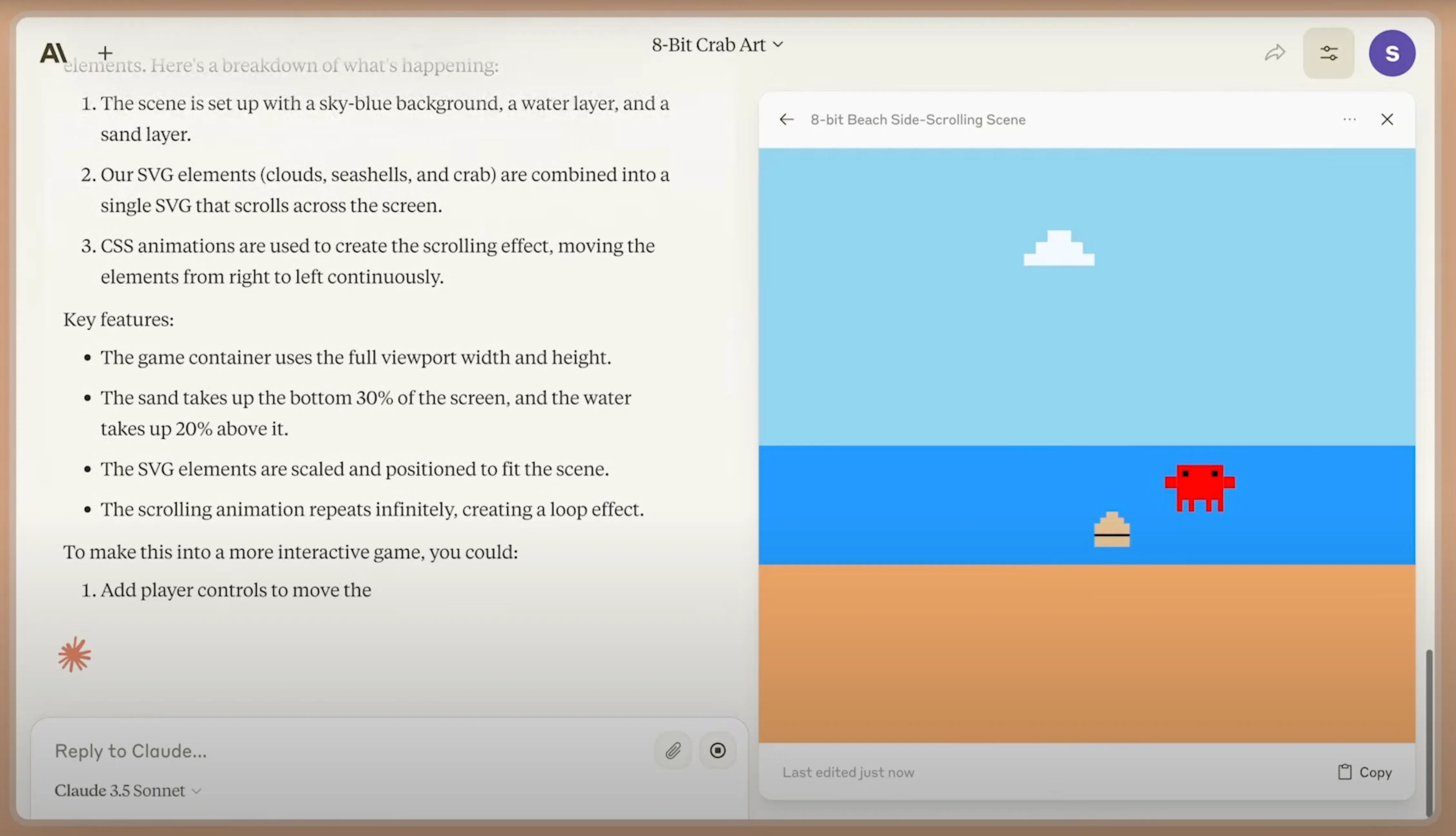
The redesigned Townie, currently in beta at val.town/townie.
Codegen
Recent advances in code generation (“codegen”), particularly in Claude 3.5 Sonnet, has enabled a completely new style of building software through conversation with an LLM.
Some of the most successful products are:
- Claude Artifacts: build interactive websites and other code through conversation. Websites can be viewed directly.
- Cursor: a fork of VSCode built for AI. It can generate changes across an codebase.
- Vercel v0: build website UIs from prompts.
- Websim: similar to Claude Artifacts, but built around “fake websites”. So going to catgifs.com will generate a website with cat gifs on the fly.
- VSCode Copilot: intelligent autocompletions of code within larger projects, for lots of programming languages.
The beauty of products like Vercel v0, Claude Artifacts, and Websim is that you immediately get a working program back even if you don’t know anything about programming! For example, in Websim you don’t even see the code, you just see the generated website.
So far these LLM-generated programs have been limited to the frontend, or copy-pasted into other places. Tools like VSCode Copilot and Cursor let you build larger software with a frontend and a backend, but now you need a place to deploy it, which is a significant barrier to non-programmers, and slows the iteration cycle.
We see many Val Town users generate their code in an LLM and then copy it into Val Town, since our “vals” (tiny full-stack webapps) get instantly deployed. We figured we’re in a good position to tighten the feedback loop of codegen to full-stack deployment, and to finally approach end-user programming:
The dream is that the full power of computers be accessible to all, that our digital worlds will be as moldable as clay.
This vision is taking shape with frontend-only apps, but if we’re really talking about “the full power of computers”, then this should include entire applications, with persistence, authentication, external API calls — really everything that professional programmers build.
I spent most of July 2024 prototyping codegen ideas in Val Town, with great results. In this blog post I’ll show you what I built and what I learned. And since I built it all within Val Town itself, it’s all open source, and you can fork it!
My prototype codegen with an instantly deployed backend and database.
Generate a full-stack app with backend and database
First I built a basic version of code generation. We can do this in only 80 lines (and only a few dependencies). You can fork it to play with it.
I used Vercel’s AI SDK to easily switch between models. To teach the LLM how to write code on Val Town, I went for a maximalist approach: I downloaded as many public vals as I could fit in a context window and put them in valleGetValsContextWindow. I also found adding our docs to the context window helpful (as raw markdown pages).
I tell it to start outputting a Typescript fence immediately (```ts), so it starts writing code right away. I then strip out the code fence later.
This is enough to generate a basic Hacker News clone with a backend and database, which is instantly deployed on its own subdomain:
Hacker News clone with backend and database, generated with gpt-4o (generation is sped up).
Advanced prototype
Over the course of several weeks, I ended up adding lots of features to this prototype:
- Side panel with code and preview
- CodeMirror for syntax highlighting
- Follow-up prompts to iterate
- Generate a new val for every iteration, so you can easily go back
- Generate multiple vals (by opening multiple tabs when submitting the form)
- Loading an existing val
- Editing code manually
- Switching between models (Claude, OpenAI) and context window size
I called this prototype VALL-E, and you can fork it yourself. Let’s look at the details of what we ran into.
Database persistence
Each Val Town user has a SQLite database powered by Turso. We ran into a problems teaching the LLM to adhere to the idiosyncrasies of Val Town SQLite. So I punted on SQLite and just got the LLM to save everything in Val Town Blob Storage, which is basically S3 lite, so it had no trouble understanding it.
Later Steve was able to fix the issues with SQLite by instructing the LLM to use his LLM-safe shim. Instead of trying to fix this through prompting, it works better to write a wrapper around the API that transforms the data into something that LLMs expects. Adapt your code to the LLM, not the LLM to your code.
Make real
You might have seen the “Make Real” demos of tldraw, where you can draw shapes on a canvas, and turn it into HTML. I made a prototype “Make Real with Backend”. For this, I put tldraw in a val (which you can fork), and put my VALL-E prototype in an iframe:
It currently only works with text prompts, but it should be easy to pass the SVGs of arbitrary drawings to the LLM, as with the original Make Draw demos.
I modified the VALL-E prototype to pass the name of generated val up to tldraw, using the postMessage API. That way you can use a previously generated val as the basis for a new one, such as when I write “add more sample stories” in the video above.
Model choice
Claude Sonnet 3.5 is clearly the best model for writing code right now. However we found that it can be very deterministic, so it can help to crank up its temperature.
We also played with gpt-4o vs gpt-4o-mini. The mini version is much cheaper but much worse, though it’s pretty good at making websites, especially when given some examples. However, we don’t want to optimize too much for cheap models, because the premier models of today will be the cheap models of tomorrow.
Putting it all together
Once I had built all this, I gave a lightning talk at an event hosted by South Park Commons. It’s 5 minutes of building lots of little apps.
Reducing costs
I started with a maximalist approach of filling the context window with as many example vals and docs as possible. Claude 3.5 Sonnet has a 200k token context window and I put hundreds of vals in there. However, a single query with a full context window costs at least $0.60 (just for the input tokens), which is a lot.
A full context window is also slower, and I hit rate limits much more quickly. I managed to get custom rate limits from Anthropic, but it’s not ideal. Let’s look at how I optimized our costs and speed.
Evals
Before cutting down our context window, I wanted to measure how good our models are, so I could see how much performance would be affected by a smaller context window.
In the world of LLMs these measurements are called “evaluations” or “evals” (presumably because people forgot that the word “benchmark” already existed). For us the general idea is this: generate a bunch of websites, then make sure they work. For this I built “E-VALL-UATOR”:
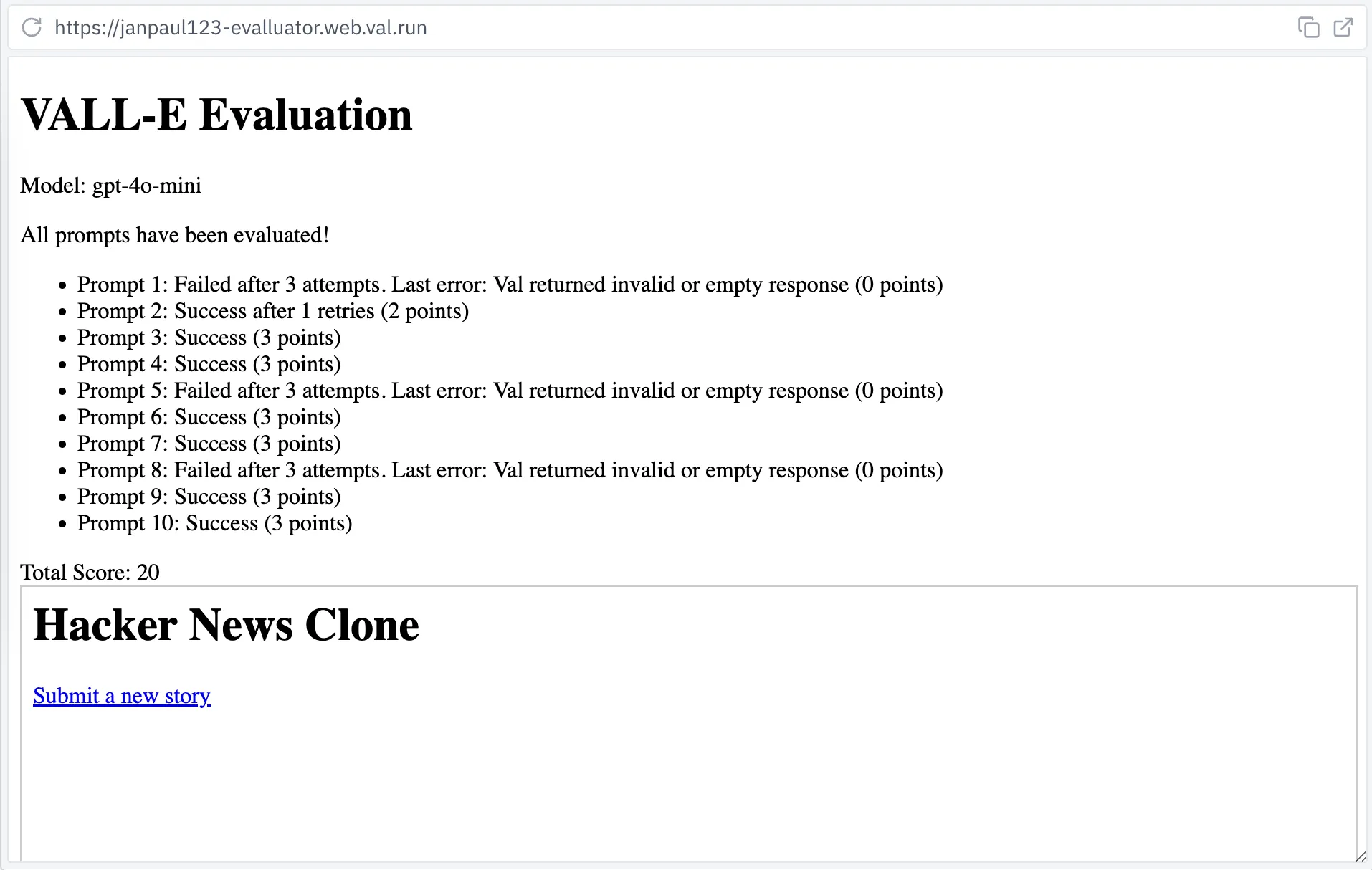
This runs some basic prompts like “Create a simple todo list app” or “Create a quiz game with a scoring system”, and then checks if it runs without errors, in which case we award 3 points. If there are errors, we’ll retry but subtract a point. The maximum score for 10 prompts is thus 30 points.
How do we evaluate if the generated code runs without errors? Let’s look at the different types of mistakes we can capture:
- Syntax errors.
- Typescript errors.
- Backend errors on
GET /. - Frontend errors on
GET /. - Frontend errors when interacting (clicking on stuff).
- Backend errors when interacting (persistence issues, issues on other pages).
- Visual issues (site doesn’t look good).
- Site doesn’t do what we expect.
For this prototype I implemented 1,3,4. I made a val (actually VALL-E made it for me) that wraps any arbitrary HTTP val, and injects a <script> tag that passes runtime errors to the parent iframe using postMessage. It also captures backend errors and generates a new HTML page for them, again with a postMessage to the parent with the error message.
In future versions we could make the prompts specify desired behavior more precisely, like “the textbox for adding a todo item should have class ‘todo-textbox’ and add the todo item when pressing ‘enter’”, and then testing the resulting code with an actual browser. For point 7 (visual issues) we could even use a screenshot service, and do a visual diff with a reference image, or ask another LLM to score the resulting design.
E-VALL-UATOR Matrix
With an eval in hand, I started trimming the context window. I made another val (or again, VALL-E really made it) that loads E-VALL-UATOR in an <iframe> with different parameters, and I modified E-VALL-UATOR to report its score to the parent using postMessage.
At this point we have iframes nested 3 levels deep (matrix => E-VALL-UATOR => VALL-E => preview), but it all works.
I sorted the example vals in the context window such that the most important ones are in the beginning. This way we can easily play with how many examples to include.

The sweet spot was 50 examples in the context window, with quite good results even with 10 examples. (Disregard our fine-tuned model. That was a bust, clearly.) This showed that at least for such a basic evaluation, we could reduce the context window quite a bit, thereby saving a bunch of money on tokens.
The team later experimented with reducing the system prompt even further to great results. The currently-deployed Townie prompt now looks almost like an abbreviated Quickstart tutorial on how to use Val Town. It only includes a single template of a val.
Generating diffs
After reducing the number of input tokens, I looked at the output tokens. These are usually more expensive, and have a much larger impact on total generation time, so reducing this can make a big difference in both cost and speed.
When iterating on existing vals it takes a lot of tokens to regenerate all the code, so I looked into diffs. The longer the val is, the more diffs help. I took inspiration from aider, which has implemented various versions of this.
It’s pretty easy to get LLMs to produce diffs in the form of SEARCH:… REPLACE:…. However, this requires repeating the entire code block that needs to be replaced. I managed to instead get LLMs to output the first and last lines of the “search” block, but omit everything in between. This is much faster and cheaper. You can try this yourself by using the “Make changes” mode in VALL-E.

However, this doesn’t come natural to LLMs, and they often go off the rails. Especially weaker models seem to have trouble with this, but even Claude 3.5 Sonnet goes wrong on occasion.
There is a lot more I’d like to experiment with, such as different diff syntaxes and semantics, including line numbers (so the model has a better point of reference), or early abort + retry if the model goes wrong.
We have recently had seom success with unified diffs, but are still experimenting heavily with this. We also have our eye on Anthropic’s Fast Edit Mode, currently in private beta.
Other ideas
Diffs in UI
Viewing diffs in the UI before accepting them can be very useful, especially when making incremental changes to large vals. This depends somewhat on the audience: non-programmers wouldn’t know what to do with diffs, while for programmers they are essential.
Note that “diffs in the UI” is completely independent from whether the LLM generates diffs or not. It is possible in either case to immediately apply the changes to the val, or to first show diffs to the user.
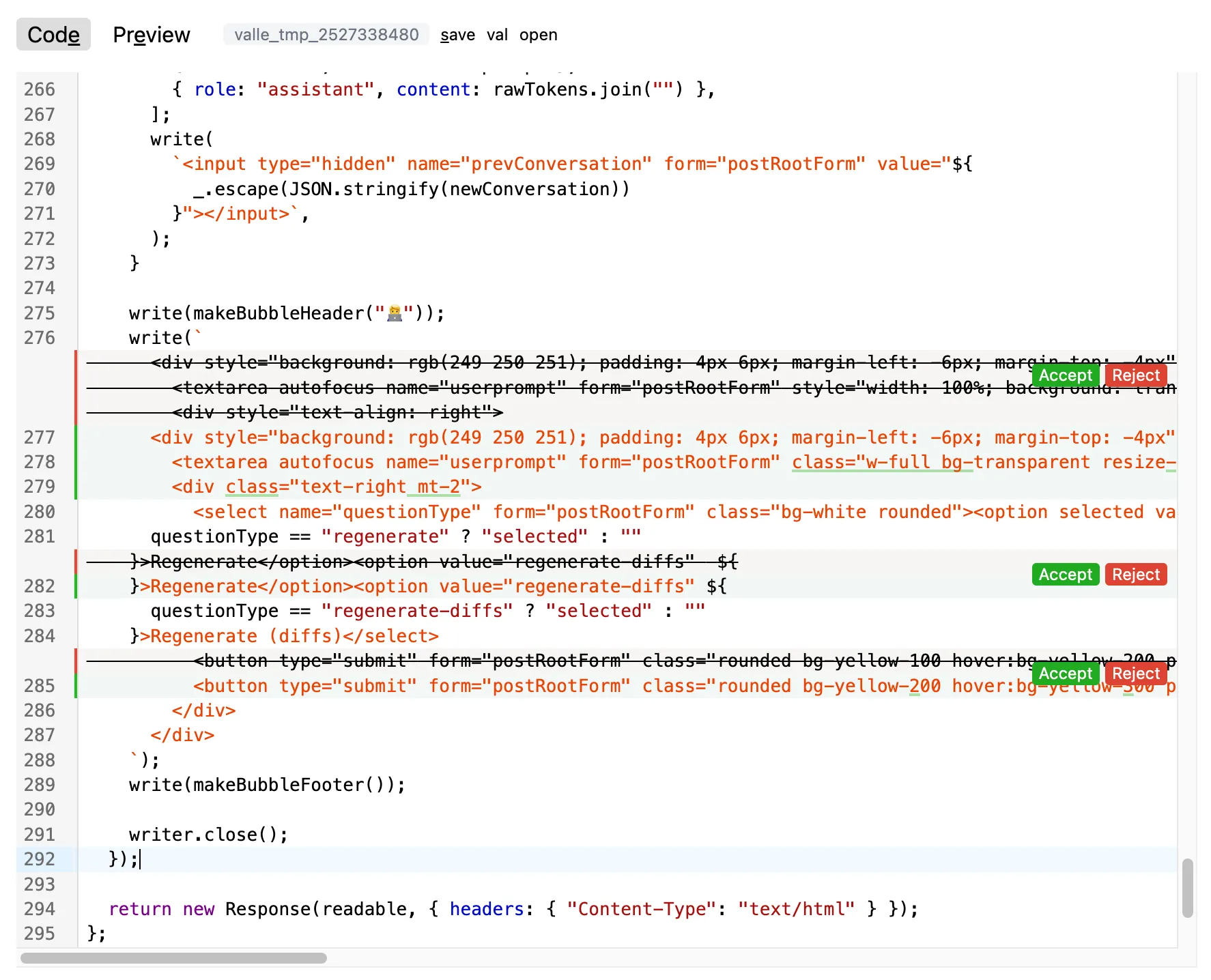
I implemented this using Codemirror’s merge view. You can use this by selecting “use diffs” in VALL-E. I ended up using mode this quite a bit for the development of VALL-E itself.
Backend vs frontend code
Vals are a single file of code, and typically include both backend and frontend code. This can be confusing LLMs. It can be confusing to humans too, and some solutions that are good for humans are good for LLMs as well, such as clearly demarkating the frontend vs backend parts of the code, or using better abstractions.
LLMs run into unique issues though. They don’t have the benefit of seeing syntax highlighting, and sometimes they like to put HTML in a long string with backticks. They then forget that they’re already within a string with backticks, and forget to escape any inner backticks.
Our currently-deployed Townie prompt is built around a client-side React template, which clearly demarcates between the frontend and backend parts of the code, so Claude knows it has to communicate between by making fetch calls on the frontend that are handled as API calls on the backend.
Iterating
When we detect an error, we can feed it back to the LLM. This was actually the first prototype that I made: IterateGPT. It would keep iterating on tricky tasks until there were no more errors. In this example I had it generate code for getting the current weather in Brooklyn, without providing it further information — it even had to think of APIs to do this from memory! This still worked remarkably well.
We can do this for all the types of mistakes we mentioned earlier (when talking about evals). We can feed syntax/Typescript/runtime errors back to the LLM; we can take screenshots of the website and feed them back; we can even have the LLM generate its own tests.
Social coding
Vals can be easily imported by other vals, which encourages people to write small vals that do one thing well, and then many people can reuse it. It’s like instant deployment for packages or libraries.
LLMs don’t take much advantage of this yet. We could search for relevant vals (RAG) and encourage the model to import them instead of generating everything from scratch.
Conclusion
It has been incredibly fun to build this, and to build it all in “user space” within Val Town. Code generation works well, especially with the latest models — and it will only get better from here, which blows my mind just to think about. These are exciting times. And even with the current models I feel like I’ve only been scratching the surface.
Let’s look back at the dream of end-user programming:
The dream is that the full power of computers be accessible to all, that our digital worlds will be as moldable as clay.
We might get there sooner than we thought.
Edit this page